



本文主要为Neural Architecture Search with reinforcement learning的详细解读
论文作者:Barret Zhph*,Quoc V.Le [来自于 Google Brain]
论文标题:Neural Architecture Search with reinforcement learning/(使用强化学习进行神经网络架构搜索)
论文会议:ILCR 2017
论文链接:https://arxiv.org/abs/1611.01578
论文代码: https://github.com/tensorflow/models
1. 概述与介绍
虽然神经网络却得了巨大的成功和发展在过去几年,从 SIFT 与 HOG,到 AlexNet,VGGNet,GoogleNet
但是想要设计一种神经网络模型仍然需要很多的专业背景知识和时间,本片文章提出了一种叫做 NAS(Neural Architecture Search)
的方法,这种方法基于梯度,用于找到非常好的 Architecture。NAS 的结构如下图所示:
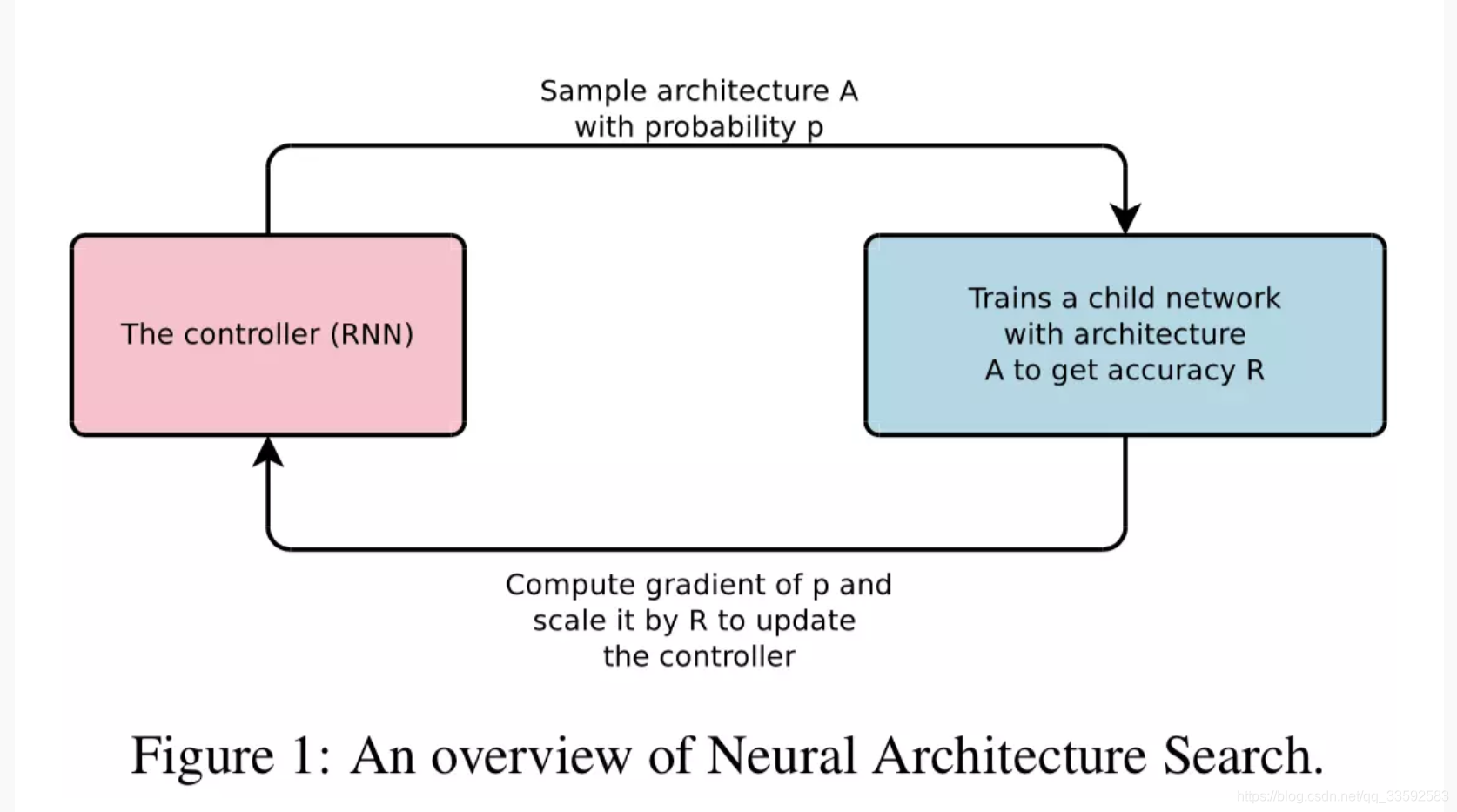
- 本文提出的方法:
- 使用 RNN 去生成神经网络的模型
- 同时使用强化学习去训练 RNN,从而希望最大化生成的架构在验证集上的最大化。
- 本文现在达到的结果:
- 计算机视觉任务: - CIFAR-10 数据集上: - test error rate: 0.09 的提升,速度是 1.05 倍更快 - 自然语言处理任务: - Penn Treebank dataset[1]: - 提出的新的 recurrent cell 超过 LSTM,还有 baseline
- 新的 cell 在 perplexity[2]上相比较 state-of-the-art 有 3.6 的提升
- PTB 数据集: - 在字符级别的语言模型任务上也是达到了 state-of-the-art
- 具体的做法: 主要就是将神经网络模型具体到变成一个可变长度的字符串,所以便于使用 RNN(控制器的作用)来生成字符串.
用于构建网络。之后训练该网络,并用网络的 accuracy 作为 reward 返回给控制器来更新控制器的参数,达到更优的策略。
2. 相关工作
Point1: 超参数优化
Hpyerparameter optimization在过去取得了很多的应用与成功,但是只能限制于固定长度的空间
中,生成一个规定网络结构和连接性的可变长度配置很困难。在实践中,如果这些方法提供了良好的初始模型这些方法往往会更好地工作
(1) 早期的解决方式: 使用贝叶斯优化方法,可以用来搜索非定长的 architecture
(2) 与本文的方法相比: 贝叶斯优化方法实在是不够通用与灵活
1 | Something we Should know: |
Point2: 现代神经进化算法
Modern neuo-evolution algorithms 在组成新的模型的时候很灵活,但是在大规模的时候
不够实用,限制主要在于是基于搜索的算法,所以运行的时候很慢同时需要启发式才能够 work well
Point3: 神经架构搜索
Neural Archhitecture Search 与程序合成和归纳编程有一些相似之处,它们从例子中搜
索程序。在机器学习中,概率性程序引导已成功用于许多环境中,比如解决简单问答,
对列表数字排序,并以少样本进行学习。
Point4: idea 的产生以及我们做了什么!
神经架构搜索中的控制器是自回归的,自回归就是预测一次的超参数,以先前的预测为条件。
这个 idea 是借鉴了端到端序列译码器对序列学习的思想。与 seq2seq learning 不同,
我们的方法优化了一个不可微的目标,child network 的 accuracy。
类似于神经机器翻译中的 BLEU[3]优化工作。与这些方法不同,
我们的方法直接从奖励信号中学习,并且没有使用有监督的 bootstrapping(自助采样方法)
与我们的工作相关的还有学习学习或元学习[4]的 idea
这是一个使用在一项任务中学到的信息来改进未来任务的通用框架。
更密切相关的是使用神经网络学习另一网络的梯度下降更新
以及使用强化学习为另一网络找到更新策略的想法。
1 | 端到端与非端到端: |
3. 方法 METHODS
Section 1. 使用 RNN 作为控制器来生成模型描述
下图所示是论文中提到如何使用 RNN 去预测生成一个简单的 conv 层的超参数
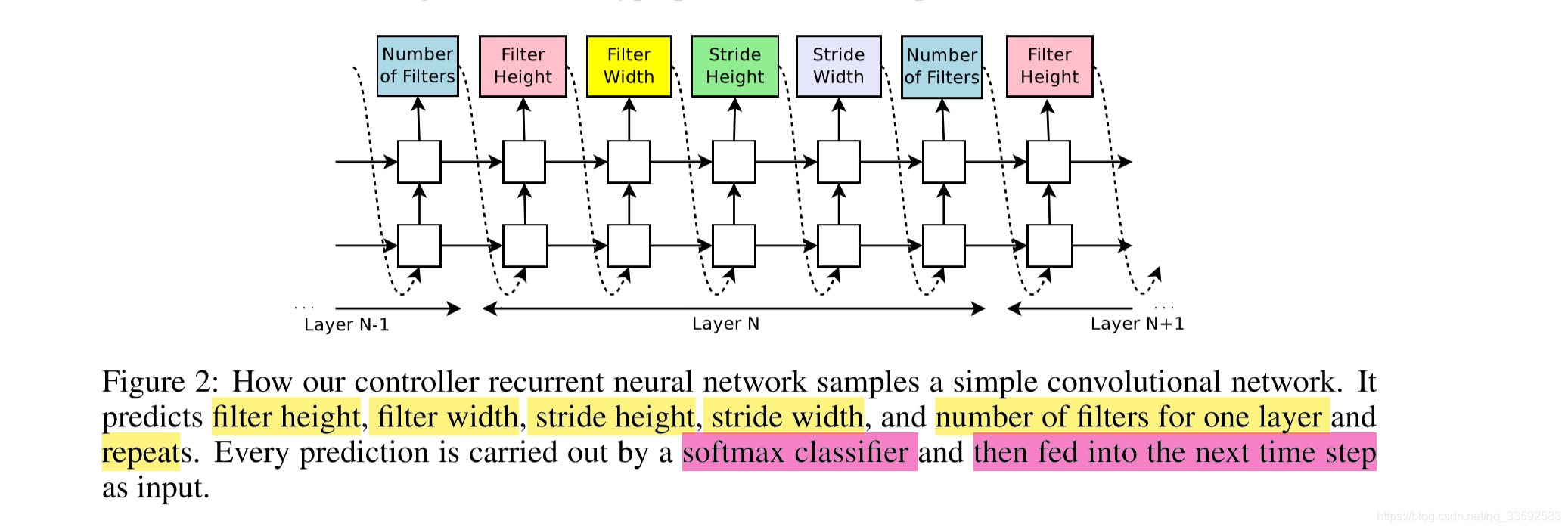
- 上图中预测的网络知识包括 conv 层,使用 RNN 预测生成 conv 层的超参数,主要包括
卷积核的 height,卷积核的 Width,卷积核滑动 stride 的 Height,卷积核滑动 stride 的 Width - 实验当中终止的条件是当网络层数达到一个值的时候就会停止
- 控制器生成一个网络结构后,使用训练数据集进行训练直到达到收敛,然后再 hand-out 验证集上进行测试
得到一个准确率。
1 | hand-out validation set: 实际上就是留出的验证集,将数据集分为训练集S,和测试集T,同时两个集合互斥 |
Section 2. 使用强化学习的思想进行训练
(1) 主要是思想为: RNN 的参数使用$\theta_{c}$表示,$controller$所预测的一系列$tokens$记为一系列的$actions$,
即$a_{1:T}$,这些 tokens 是为了$Child network$,子网络再验证集上得到的准确率用$R$进行表示,这种准确率称为
$reward signal$,并且使用强化学习来训练$controller$
(2) 目标函数: 如下图所示,实际上就是需要$maximize reward$来找到最优的结构
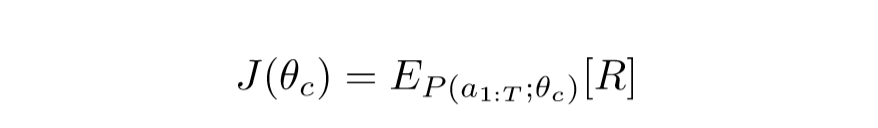
由于奖励信号 R 是不可微分的,因此使用策略梯度迭代的去更新$\theta_{c}$,在本文中,使用到来自 $Williams (1992)$ 的强化学习规则
如下图所示
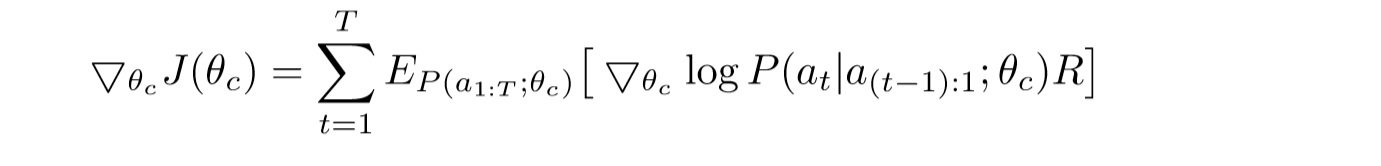
对于上面这个等式实际上就约等于如下所示的等式:
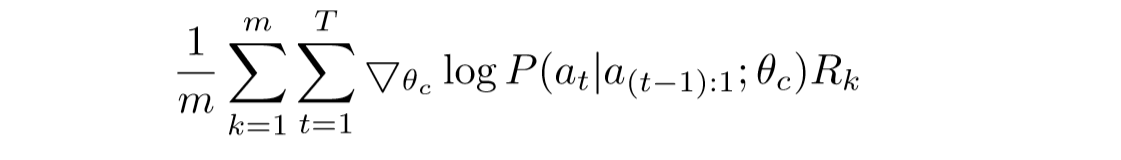
公式推导如下所示:
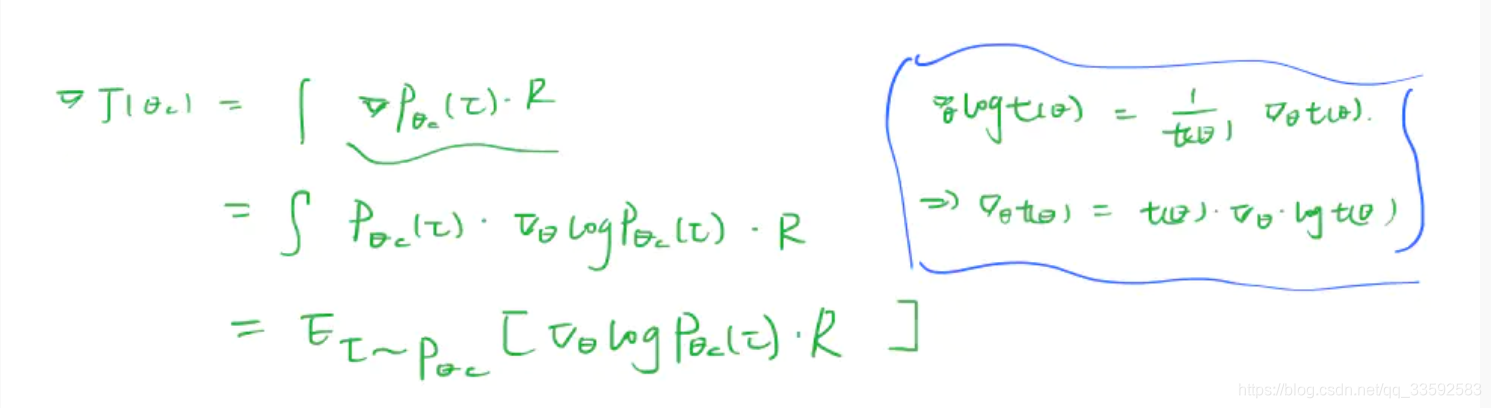
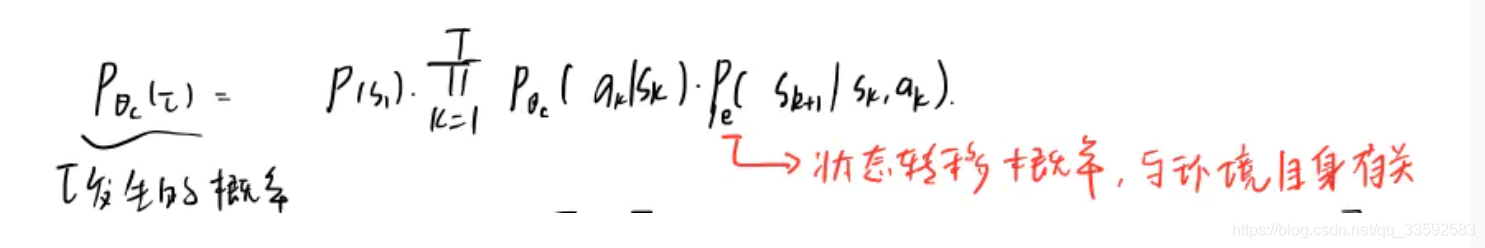
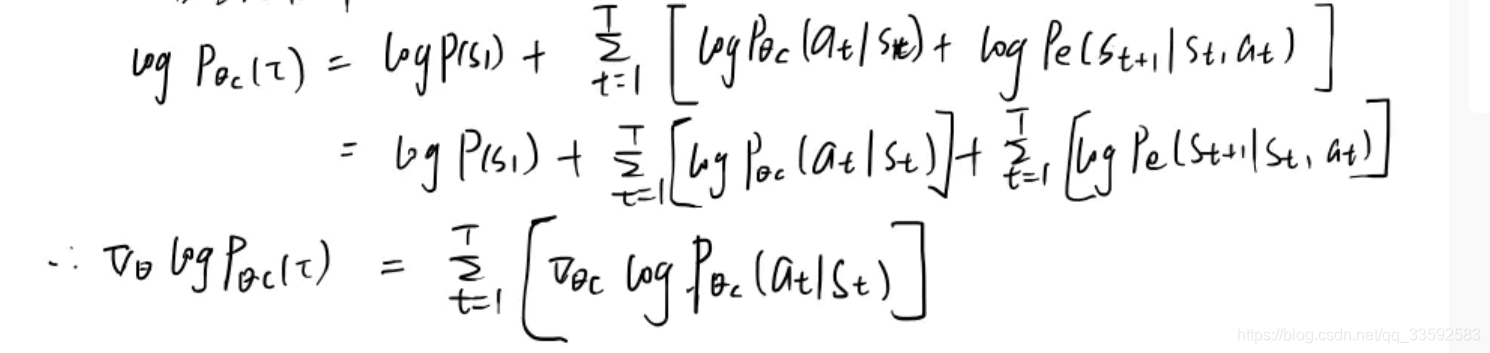
1 | 公式参数解读: |
上述的更新算法是对梯度的无偏估计,但是缺点在于方差太高,解决方法如下图所示,采用了一个 baseline 函数
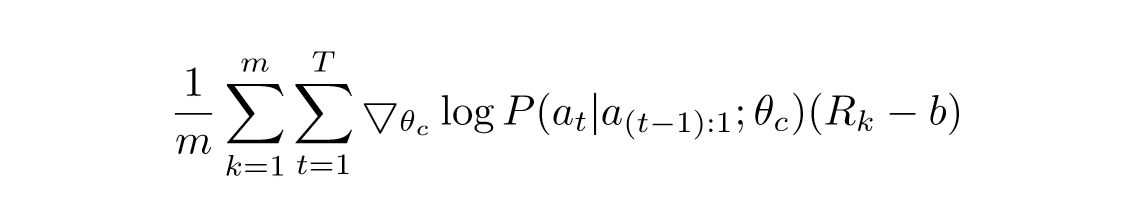
其中$b$不依赖于当前的 action,那么其仍是无偏梯度估计,且$b$是前面结构准确度的指数平均指标(Exponential Moving Average,EMA)
1 | 无偏估计:无偏估计是用样本统计量来估计总体参数时的一种无偏推断。估计量的数学期望等于被估计参数的真实值,则称此估计量为被估计参数的无偏估计,即具有无偏性,是一种用于评价估计量优良性的准则。无偏估计的意义是:在多次重复下,它们的平均数接近所估计的参数真值。无偏估计常被应用于测验分数统计中。 |
(3) 使用并行算法和异步来进行加速学习(氪金的味道,Google 亲爹)
每一次用于更新 controller 的参数$\theta_{c}$的梯度都对应于一个子网络训练达到收敛。但是因为子网络众多,
且每次训练收敛耗时长,所以使用 分布式训练和异步参数更新的方法来加速 controller 的学习速度。具体结构如下
图所示:
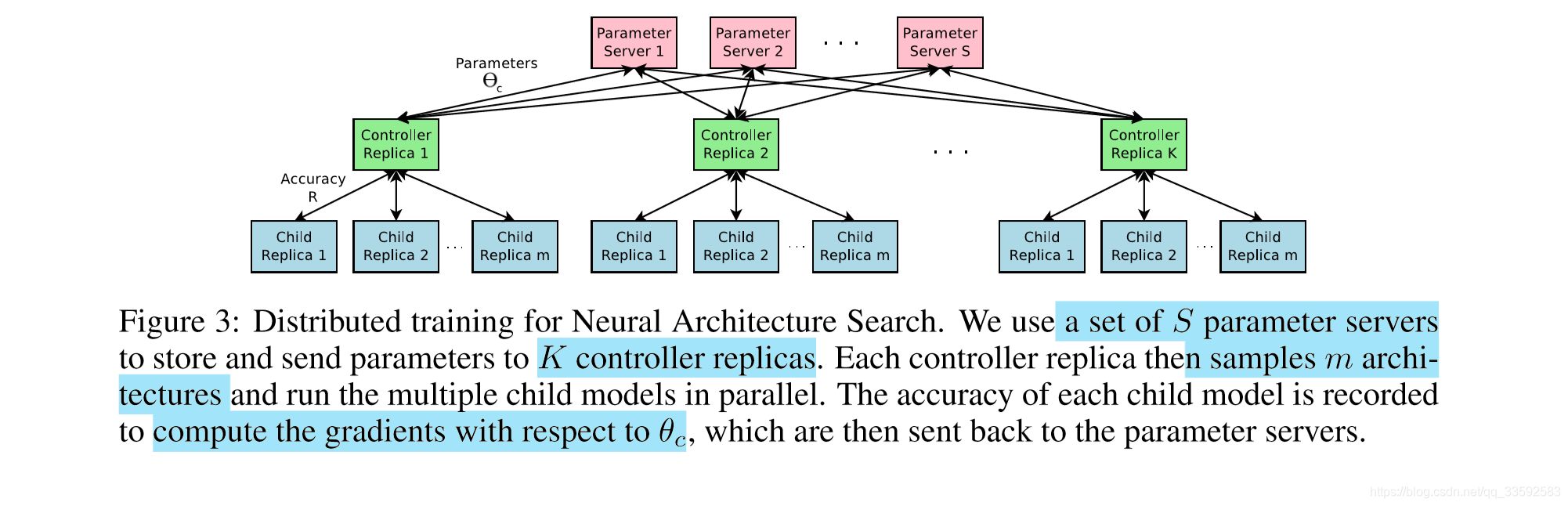
主要就是有 S 个 Parameter Server 用于存储 K 个 Controller 复制体的共享参数,然后然后每个
Controller Replica 生成 m 个并行训练的自网络。
controller 会根据 m 个子网络结构在收敛时得到的结果收集得到梯度值,然后为了更新所有 Controller Replica,会把梯度值传递给 Parameter Server。
在本文中,当训练迭代次数超过一定次数则认为子网络收敛。
Section 3: 使用跳跃连接和其他 Layer Types 来提升架构的复杂度
这个 Section 实际就是讲需要使用 Skip ConnecionS(ResNet 结构)和 branching Layers(层分叉,GoogleNet 结构)。
同时为了准确预测 connections,本文使用了基于注意力机制的 set-selection type attenion 方法。
方法:
(1)每个 layer 添加一个 anchor point, 则经过 anchor point, RNN Controller 有一个 hidden state $h_i$
(2)在 N 层,根据 sigmoid 函数采样 j 是否连接到 i layer,sigmoid 函数如下所示:
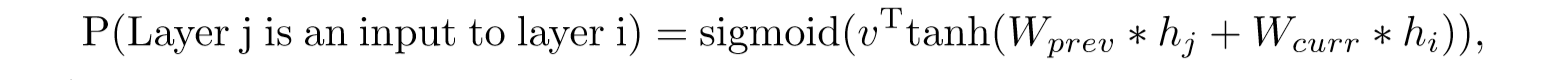
上式中$W_{curr},W_{prev},v$是可以学习的参数
下图实质表示的是如何使用 $skip connections$ 去决定那一层是其想要输入的当前层
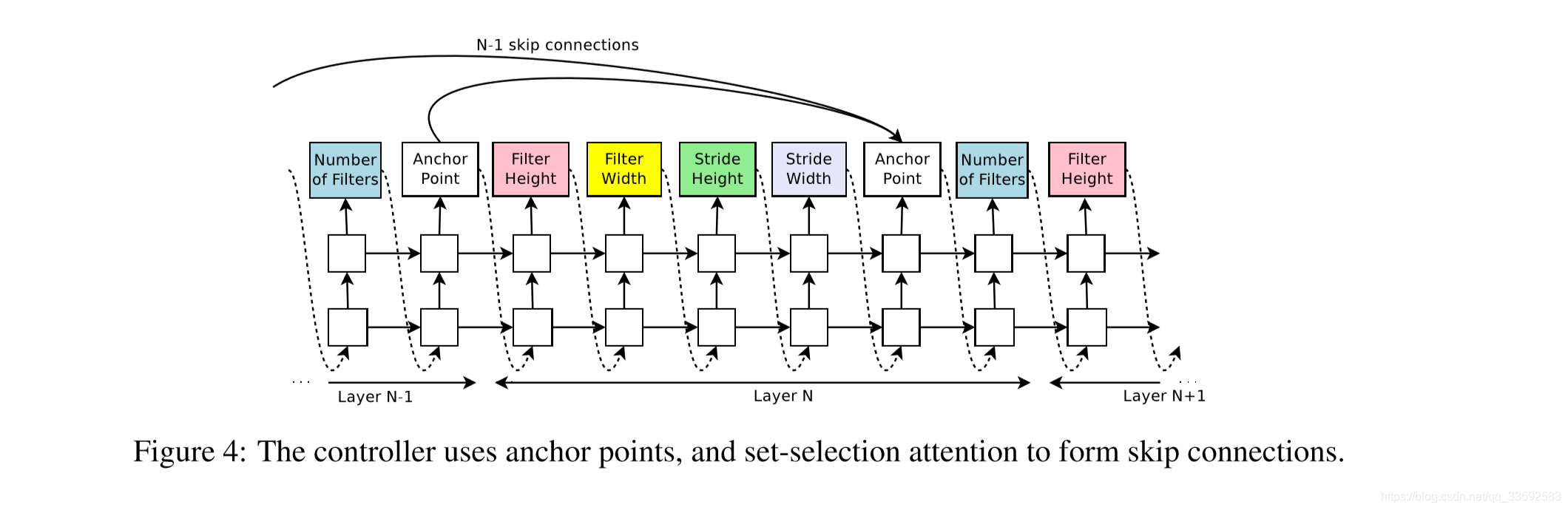
在本文当中对几个问题进行了处理:
(1) 如果没有输入,那么原始图像作为输入,看成是 $input layer$
(2) $layer$ 输出可能没被送到任何其他 $layers$:都送到$classifier$
(3) 如果需要 $concatenated$ 的输入层有不同的$size$,那么小一点的层通过补 0 来保证一样大小
添加其他类型 $layers$
1 | pooling, batchnorm, 甚至是Learning rate |
RNN Controller 首先预测 layer type,再预测相关的 hyperparameters
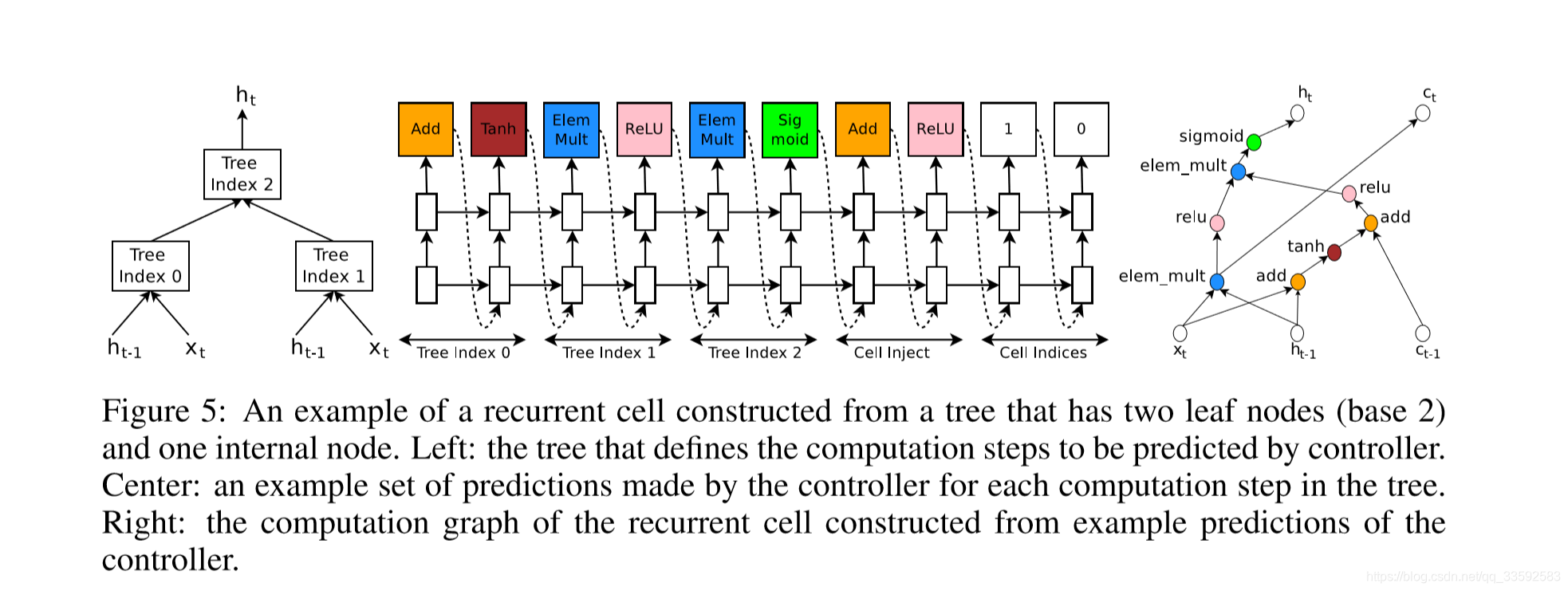
Section 4: 生成 RECURRENT CELL 架构
主要是讲如何生成递归单元结构的具体细节,使用树结构来描述网络结构,这样也便于便利结点
,其中每棵树由两个叶子节点(0,1)和中间节点(用 2 表示)组成.这种结构也可以称为”base 2”结构。
具体如下所示:
4. 实验与结果
主要是在 CIFAR-10 数据集上进行图像分类以及在 Penn Treebank 上进行 language modeling 任务
其中数据集,baseline 模型以及超参设置,具体可见论文。
5.结论与总结
(1) NAS 在生成网络的时候之前需要固定网络的结构,或者是说需要固定网络的层数。
(2) 以生成 CNN 网络为例,代码中默认最大层数参数 max_layers=2,当然也可以人为修改。
(3) 而 controller 其实就是一个 RNN 网络,其输出数据表示某一层中各个节点的参数,各个参数是按顺序输出的。
例如代码中是按照[cnn_filter_size,cnn_num_filters,max_pool_ksize,cnn_dropout_rates] 输出。
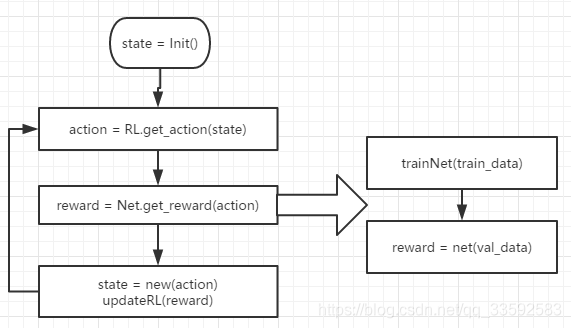
1 | 伪代码: |
从上面的伪代码可以看出每次采样得到的模型都需要在训练集上训练到收敛,然后再根据在验证集上得到的 reward 更新。所以 NAS 其本质是在离散搜索空间进行搜索,
而且网络拓扑结构是固定的,并且训练时间较长。
代码复现:https://github.com/wallarm/nascell-automl
1 | 一些内容的解释: |
1 | 论文写作鉴赏: |
1 | 参考文献: |


